Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress
spec:
rules:
- host: "nginx-ingress.kubernetes.saasx.io"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: my-nginx-svc
port:
number: 80apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress
spec:
rules:
- host: "wp-ingress.kubernetes.saasx.io"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: wordpress
port:
number: 80.spec.selector field defines how the created ReplicaSet finds which Pods to manage. In this case, you select a label that is defined in the Pod template (app: nginx). However, more sophisticated selection rules are possible, as long as the Pod template itself satisfies the rule.kubectl annotate deployment/nginx-deployment kubernetes.io/change-cause="image updated to 1.16.1"DeploymentRollback event for rolling back to revision 2 is generated from Deployment controller.maxUnavailable requirement that you mentioned above. Check out the rollout status:reason: ReplicaSetUpdatedendpoints resource or retrieve multiple A records from DNS.Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment "nginx-deployment" successfully rolled outNAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 18sNAME DESIRED CURRENT READY AGE
nginx-deployment-75675f5897 3 3 3 18sNAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-75675f5897-7ci7o 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
nginx-deployment-75675f5897-kzszj 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
nginx-deployment-75675f5897-qqcnn 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897kubectl rollout status deployment/nginx-deploymentWaiting for rollout to finish: 2 out of 3 new replicas have been updated...deployment "nginx-deployment" successfully rolled outkubectl get podsNAME READY STATUS RESTARTS AGE
nginx-deployment-1564180365-khku8 1/1 Running 0 14s
nginx-deployment-1564180365-nacti 1/1 Running 0 14s
nginx-deployment-1564180365-z9gth 1/1 Running 0 14skubectl describe deploymentsName: nginx-deployment
Namespace: default
CreationTimestamp: Thu, 30 Nov 2017 10:56:25 +0000
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=2
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.16.1
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-1564180365 (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 2m deployment-controller Scaled up replica set nginx-deployment-2035384211 to 3
Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 1
Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 2
Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 2
Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 1
Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 3
Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 0kubectl get rsNAME DESIRED CURRENT READY AGE
nginx-deployment-1564180365 3 3 3 25s
nginx-deployment-2035384211 0 0 0 36s
nginx-deployment-3066724191 1 1 0 6skubectl get podsNAME READY STATUS RESTARTS AGE
nginx-deployment-1564180365-70iae 1/1 Running 0 25s
nginx-deployment-1564180365-jbqqo 1/1 Running 0 25s
nginx-deployment-1564180365-hysrc 1/1 Running 0 25s
nginx-deployment-3066724191-08mng 0/1 ImagePullBackOff 0 6skubectl describe deploymentName: nginx-deployment
Namespace: default
CreationTimestamp: Tue, 15 Mar 2016 14:48:04 -0700
Labels: app=nginx
Selector: app=nginx
Replicas: 3 desired | 1 updated | 4 total | 3 available | 1 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.161
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
OldReplicaSets: nginx-deployment-1564180365 (3/3 replicas created)
NewReplicaSet: nginx-deployment-3066724191 (1/1 replicas created)
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-2035384211 to 3
22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 1
22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 2
22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 2
21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 1
21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 3
13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 0
13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-3066724191 to 1kubectl rollout history deployment/nginx-deployment --revision=2deployments "nginx-deployment" revision 2
Labels: app=nginx
pod-template-hash=1159050644
Annotations: kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1
Containers:
nginx:
Image: nginx:1.16.1
Port: 80/TCP
QoS Tier:
cpu: BestEffort
memory: BestEffort
Environment Variables: <none>
No volumes.kubectl get deployment nginx-deploymentNAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 30mkubectl describe deployment nginx-deploymentName: nginx-deployment
Namespace: default
CreationTimestamp: Sun, 02 Sep 2018 18:17:55 -0500
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=4
kubernetes.io/change-cause=kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.16.1
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-c4747d96c (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 12m deployment-controller Scaled up replica set nginx-deployment-75675f5897 to 3
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 1
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 2
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 2
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 1
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 3
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 0
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-595696685f to 1
Normal DeploymentRollback 15s deployment-controller Rolled back deployment "nginx-deployment" to revision 2
Normal ScalingReplicaSet 15s deployment-controller Scaled down replica set nginx-deployment-595696685f to 0kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1deployment.apps/nginx-deployment image updatedkubectl rollout history deployment/nginx-deploymentdeployments "nginx"
REVISION CHANGE-CAUSE
1 <none>kubectl get rsNAME DESIRED CURRENT READY AGE
nginx-2142116321 3 3 3 2mkubectl set resources deployment/nginx-deployment -c=nginx --limits=cpu=200m,memory=512Mideployment.apps/nginx-deployment resource requirements updatedkubectl rollout resume deployment/nginx-deploymentdeployment.apps/nginx-deployment resumedkubectl get rs -wNAME DESIRED CURRENT READY AGE
nginx-2142116321 2 2 2 2m
nginx-3926361531 2 2 0 6s
nginx-3926361531 2 2 1 18s
nginx-2142116321 1 2 2 2m
nginx-2142116321 1 2 2 2m
nginx-3926361531 3 2 1 18s
nginx-3926361531 3 2 1 18s
nginx-2142116321 1 1 1 2m
nginx-3926361531 3 3 1 18s
nginx-3926361531 3 3 2 19s
nginx-2142116321 0 1 1 2m
nginx-2142116321 0 1 1 2m
nginx-2142116321 0 0 0 2m
nginx-3926361531 3 3 3 20skubectl get rsNAME DESIRED CURRENT READY AGE
nginx-2142116321 0 0 0 2m
nginx-3926361531 3 3 3 28sapiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# modify replicas according to your case
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3kubectl apply -f https://kubernetes.io/examples/controllers/frontend.yamlkubectl get rsNAME DESIRED CURRENT READY AGE
frontend 3 3 3 6skubectl describe rs/frontendName: frontend
Namespace: default
Selector: tier=frontend
Labels: app=guestbook
tier=frontend
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apps/v1","kind":"ReplicaSet","metadata":{"annotations":{},"labels":{"app":"guestbook","tier":"frontend"},"name":"frontend",...
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: tier=frontend
Containers:
php-redis:
Image: gcr.io/google_samples/gb-frontend:v3
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 117s replicaset-controller Created pod: frontend-wtsmm
Normal SuccessfulCreate 116s replicaset-controller Created pod: frontend-b2zdv
Normal SuccessfulCreate 116s replicaset-controller Created pod: frontend-vcmtskubectl get podsNAME READY STATUS RESTARTS AGE
frontend-b2zdv 1/1 Running 0 6m36s
frontend-vcmts 1/1 Running 0 6m36s
frontend-wtsmm 1/1 Running 0 6m36skubectl get pods frontend-b2zdv -o yamlapiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2020-02-12T07:06:16Z"
generateName: frontend-
labels:
tier: frontend
name: frontend-b2zdv
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: frontend
uid: f391f6db-bb9b-4c09-ae74-6a1f77f3d5cf
...apiVersion: v1
kind: Pod
metadata:
name: pod1
labels:
tier: frontend
spec:
containers:
- name: hello1
image: gcr.io/google-samples/hello-app:2.0
---
apiVersion: v1
kind: Pod
metadata:
name: pod2
labels:
tier: frontend
spec:
containers:
- name: hello2
image: gcr.io/google-samples/hello-app:1.0kubectl apply -f https://kubernetes.io/examples/pods/pod-rs.yamlkubectl get podsNAME READY STATUS RESTARTS AGE
frontend-b2zdv 1/1 Running 0 10m
frontend-vcmts 1/1 Running 0 10m
frontend-wtsmm 1/1 Running 0 10m
pod1 0/1 Terminating 0 1s
pod2 0/1 Terminating 0 1skubectl apply -f https://kubernetes.io/examples/pods/pod-rs.yamlkubectl apply -f https://kubernetes.io/examples/controllers/frontend.yamlkubectl get podsNAME READY STATUS RESTARTS AGE
frontend-hmmj2 1/1 Running 0 9s
pod1 1/1 Running 0 36s
pod2 1/1 Running 0 36smatchLabels:
tier: frontendkubectl proxy --port=8080
curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \
-H "Content-Type: application/json"kubectl proxy --port=8080
curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \
-H "Content-Type: application/json"apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: frontend-scaler
spec:
scaleTargetRef:
kind: ReplicaSet
name: frontend
minReplicas: 3
maxReplicas: 10
targetCPUUtilizationPercentage: 50kubectl apply -f https://k8s.io/examples/controllers/hpa-rs.yamlkubectl autoscale rs frontend --max=10 --min=3 --cpu-percent=50apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3
selector:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80kubectl apply -f https://k8s.io/examples/controllers/replication.yamlreplicationcontroller/nginx createdkubectl describe replicationcontrollers/nginxName: nginx
Namespace: default
Selector: app=nginx
Labels: app=nginx
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 0 Running / 3 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- ---- ------ -------
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-qrm3m
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-3ntk0
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-4ok8vPods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failedpods=$(kubectl get pods --selector=app=nginx --output=jsonpath={.items..metadata.name})
echo $podsnginx-3ntk0 nginx-4ok8v nginx-qrm3mapiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80kubectl apply -f https://k8s.io/examples/controllers/nginx-deployment.yamlNAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 0/3 0 0 1skubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.16.1kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 36skubectl get rsNAME DESIRED CURRENT READY AGE
nginx-deployment-1564180365 3 3 3 6s
nginx-deployment-2035384211 0 0 0 36skubectl set image deployment/nginx-deployment nginx=nginx:1.161deployment.apps/nginx-deployment image updatedkubectl rollout status deployment/nginx-deploymentkubectl rollout history deployment/nginx-deploymentdeployments "nginx-deployment"
REVISION CHANGE-CAUSE
1 kubectl apply --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml
2 kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1
3 kubectl set image deployment/nginx-deployment nginx=nginx:1.161kubectl rollout undo deployment/nginx-deploymentdeployment.apps/nginx-deployment rolled backkubectl rollout undo deployment/nginx-deployment --to-revision=2deployment.apps/nginx-deployment rolled backkubectl scale deployment/nginx-deployment --replicas=10deployment.apps/nginx-deployment scaledkubectl autoscale deployment/nginx-deployment --min=10 --max=15 --cpu-percent=80deployment.apps/nginx-deployment scaledkubectl get deployNAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 10 10 10 10 50skubectl set image deployment/nginx-deployment nginx=nginx:sometagdeployment.apps/nginx-deployment image updatedkubectl get deployNAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 15 18 7 8 7mkubectl get rsNAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 7 7 0 7m
nginx-deployment-618515232 11 11 11 7mkubectl get deployNAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 3 3 3 3 1mkubectl get rsNAME DESIRED CURRENT READY AGE
nginx-2142116321 3 3 3 1mkubectl rollout status deployment/nginx-deploymentWaiting for rollout to finish: 2 of 3 updated replicas are available...
deployment "nginx-deployment" successfully rolled outecho $?0kubectl patch deployment/nginx-deployment -p '{"spec":{"progressDeadlineSeconds":600}}'deployment.apps/nginx-deployment patchedkubectl describe deployment nginx-deployment<...>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
ReplicaFailure True FailedCreate
<...>status:
availableReplicas: 2
conditions:
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: Replica set "nginx-deployment-4262182780" is progressing.
reason: ReplicaSetUpdated
status: "True"
type: Progressing
- lastTransitionTime: 2016-10-04T12:25:42Z
lastUpdateTime: 2016-10-04T12:25:42Z
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: 'Error creating: pods "nginx-deployment-4262182780-" is forbidden: exceeded quota:
object-counts, requested: pods=1, used: pods=3, limited: pods=2'
reason: FailedCreate
status: "True"
type: ReplicaFailure
observedGeneration: 3
replicas: 2
unavailableReplicas: 2Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing False ProgressDeadlineExceeded
ReplicaFailure True FailedCreateConditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailablekubectl rollout status deployment/nginx-deploymentWaiting for rollout to finish: 2 out of 3 new replicas have been updated...
error: deployment "nginx" exceeded its progress deadlineecho $?1apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
serviceName: "nginx"
replicas: 3 # by default is 1
minReadySeconds: 10 # by default is 0
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: registry.k8s.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1GiapiVersion: apps/v1
kind: StatefulSet
...
spec:
persistentVolumeClaimRetentionPolicy:
whenDeleted: Retain
whenScaled: Delete
...apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# these tolerations are to have the daemonset runnable on control plane nodes
# remove them if your control plane nodes should not run pods
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/logkubectl apply -f https://k8s.io/examples/controllers/daemonset.yamlnodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchFields:
- key: metadata.name
operator: In
values:
- target-host-nameapiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
kubectl apply -f https://kubernetes.io/examples/controllers/job.yamljob.batch/pi created
Name: pi
Namespace: default
Selector: batch.kubernetes.io/controller-uid=c9948307-e56d-4b5d-8302-ae2d7b7da67c
Labels: batch.kubernetes.io/controller-uid=c9948307-e56d-4b5d-8302-ae2d7b7da67c
batch.kubernetes.io/job-name=pi
...
Annotations: batch.kubernetes.io/job-tracking: ""
Parallelism: 1
Completions: 1
Start Time: Mon, 02 Dec 2019 15:20:11 +0200
Completed At: Mon, 02 Dec 2019 15:21:16 +0200
Duration: 65s
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
Pod Template:
Labels: batch.kubernetes.io/controller-uid=c9948307-e56d-4b5d-8302-ae2d7b7da67c
batch.kubernetes.io/job-name=pi
Containers:
pi:
Image: perl:5.34.0
Port: <none>
Host Port: <none>
Command:
perl
-Mbignum=bpi
-wle
print bpi(2000)
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 21s job-controller Created pod: pi-xf9p4
Normal Completed 18s job-controller Job completedpods=$(kubectl get pods --selector=batch.kubernetes.io/job-name=pi --output=jsonpath='{.items[*].metadata.name}')
echo $podspi-5rwd7kubectl logs $podskubectl logs jobs/pi3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456485669234603486104543266482133936072602491412737245870066063155881748815209209628292540917153643678925903600113305305488204665213841469519415116094330572703657595919530921861173819326117931051185480744623799627495673518857527248912279381830119491298336733624406566430860213949463952247371907021798609437027705392171762931767523846748184676694051320005681271452635608277857713427577896091736371787214684409012249534301465495853710507922796892589235420199561121290219608640344181598136297747713099605187072113499999983729780499510597317328160963185950244594553469083026425223082533446850352619311881710100031378387528865875332083814206171776691473035982534904287554687311595628638823537875937519577818577805321712268066130019278766111959092164201989380952572010654858632788659361533818279682303019520353018529689957736225994138912497217752834791315155748572424541506959508295331168617278558890750983817546374649393192550604009277016711390098488240128583616035637076601047101819429555961989467678374494482553797747268471040475346462080466842590694912933136770289891521047521620569660240580381501935112533824300355876402474964732639141992726042699227967823547816360093417216412199245863150302861829745557067498385054945885869269956909272107975093029553211653449872027559602364806654991198818347977535663698074265425278625518184175746728909777727938000816470600161452491921732172147723501414419735685481613611573525521334757418494684385233239073941433345477624168625189835694855620992192221842725502542568876717904946016534668049886272327917860857843838279679766814541009538837863609506800642251252051173929848960841284886269456042419652850222106611863067442786220391949450471237137869609563643719172874677646575739624138908658326459958133904780275901apiVersion: batch/v1
kind: Job
metadata:
name: job-pod-failure-policy-example
spec:
completions: 12
parallelism: 3
template:
spec:
restartPolicy: Never
containers:
- name: main
image: docker.io/library/bash:5
command: ["bash"] # example command simulating a bug which triggers the FailJob action
args:
- -c
- echo "Hello world!" && sleep 5 && exit 42
backoffLimit: 6
podFailurePolicy:
rules:
- action: FailJob
onExitCodes:
containerName: main # optional
operator: In # one of: In, NotIn
values: [42]
- action: Ignore # one of: Ignore, FailJob, Count
onPodConditions:
- type: DisruptionTarget # indicates Pod disruptionapiVersion: batch/v1
kind: Job
metadata:
name: pi-with-timeout
spec:
backoffLimit: 5
activeDeadlineSeconds: 100
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: NeverapiVersion: batch/v1
kind: Job
metadata:
name: pi-with-ttl
spec:
ttlSecondsAfterFinished: 100
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Neverkubectl get job myjob -o yamlapiVersion: batch/v1
kind: Job
metadata:
name: myjob
spec:
suspend: true
parallelism: 1
completions: 5
template:
spec:
...kubectl patch job/myjob --type=strategic --patch '{"spec":{"suspend":true}}'kubectl patch job/myjob --type=strategic --patch '{"spec":{"suspend":false}}'kubectl get jobs/myjob -o yamlapiVersion: batch/v1
kind: Job
# .metadata and .spec omitted
status:
conditions:
- lastProbeTime: "2021-02-05T13:14:33Z"
lastTransitionTime: "2021-02-05T13:14:33Z"
status: "True"
type: Suspended
startTime: "2021-02-05T13:13:48Z"kubectl describe jobs/myjobName: myjob
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 12m job-controller Created pod: myjob-hlrpl
Normal SuccessfulDelete 11m job-controller Deleted pod: myjob-hlrpl
Normal Suspended 11m job-controller Job suspended
Normal SuccessfulCreate 3s job-controller Created pod: myjob-jvb44
Normal Resumed 3s job-controller Job resumedkubectl get job old -o yamlkind: Job
metadata:
name: old
...
spec:
selector:
matchLabels:
batch.kubernetes.io/controller-uid: a8f3d00d-c6d2-11e5-9f87-42010af00002
...kind: Job
metadata:
name: new
...
spec:
manualSelector: true
selector:
matchLabels:
batch.kubernetes.io/controller-uid: a8f3d00d-c6d2-11e5-9f87-42010af00002
...deployment.apps/nginx-deployment image updatedkubectl edit deployment/nginx-deploymentdeployment.apps/nginx-deployment editedWaiting for rollout to finish: 1 out of 3 new replicas have been updated...kubectl get rsNAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 5 5 0 9s
nginx-deployment-618515232 8 8 8 1mkubectl rollout pause deployment/nginx-deploymentdeployment.apps/nginx-deployment paused


aws rds create-db-snapshot /
--db-instance-identifier sourcedbinstance /
--db-snapshot-identifier dbsnapshotinstanceBurst Duration = (credit Balance) / [(burst IOPS) – 3(Storage size in GB)]
# mysqldump -u user -p[user_password] [database_name] > backupfile.sql
aws rds restore-db-instance-from-s3 \
--allocated-storage 125 \
--db-instance-identifier tddbidentifier \
--db-instance-class db.m4.small \
--engine mysql \
--master-user-name masterawsuser \
--master-user-password masteruserpassword \
--s3-bucket-name tpbucket \
--s3-ingestion-role-arn arn:aws:iam::account-number:role/rolename \
--s3-prefix bucketprefix \
--source-engine mysql \
--source-engine-version 5.6.27aws rds create-db-instance-read-replica \
--db-instance-identifier myreadreplica \
--source-db-instance-identifier mydbinstanceaws rds create-db-instance-read-replica \
--db-instance-identifier readreplica_name \
--region target_region_name
--db-subnet-group-name subnet_name
--source-db-instance-identifier arn:aws:rds:region_name:11323467889012:db:mysql_instance1
mysqldump -h RDS instance endpoint \
-u user \
-p password \
--port=3306 \
--single-transaction \
--routines \
--triggers \
--databases database database2 \
--compress \
--compact | mysql \
-h MariaDB host \
-u master user \
-p password \
--port 3306 



1- Run 1st Instance with aws console
2- Run 2nd instance with aws cli
3- Create EFS filesystem
4- attach EFS to 1st and 2nd instance
5- mount in fstab and reboot instances
{
"Version": "2018-09-11",
"Statement": [
{
"Sid": "AllowCreateDBInstanceOnly",
"Effect": "Allow",
"Action": [
"rds:CreateDBInstance"
],
"Resource": [
"arn:aws:rds:*:123456789012:db:test*",
"arn:aws:rds:*:123456789012:og:default*",
"arn:aws:rds:*:123456789012:pg:default*",
"arn:aws:rds:*:123456789012:subgrp:default"
],
"Condition": {
"StringEquals": {
"rds:DatabaseEngine": "mysql",
"rds:DatabaseClass": "db.t2.micro"
}
}
}
]
}{
"Version":"2012-10-17",
"Statement":[
{
"Sid":"AllowRDSDescribe",
"Effect":"Allow",
"Action":"rds:Describe*",
"Resource":"*"
}
]
}{
"Version":"2012-10-17",
"Statement":[
{
"Sid":"DenyDelete1",
"Effect":"Deny",
"Action":"rds:DeleteDBInstance",
"Resource":"arn:aws:rds:us-west-2:123456789012:db:my-mysql-instance"
}
]
}apiVersion: apps/v1
kind: ReplicaSet
metadata:
namespace: yourname
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# modify replicas according to your case
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3echo -n 'devops' | base64apiVersion: v1
kind: Secret
metadata:
namespace: yourname
name: mysql-pass
type: Opaque
data:
password: ZGV2b3BzapiVersion: v1
kind: PersistentVolumeClaim
metadata:
namespace: yourname
name: mysql-pv-claim
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 40GiapiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: yourname
name: wordpress-mysql
labels:
app: wordpress
spec:
selector:
matchLabels:
app: wordpress
tier: mysql
template:
metadata:
labels:
app: wordpress
tier: mysql
spec:
containers:
- image: mysql:5.6
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claimapiVersion: v1
kind: Service
metadata:
namespace: yourname
name: wordpress-mysql
labels:
app: wordpress
spec:
ports:
- port: 3306
selector:
app: wordpress
tier: mysql


m6idn.metalm6in.metalm7g.metalmac1.metalmac2.metal
open-source, client-side TypeScript based JavaScript framework
Laravel is a PHP based web-framework for building high-end web applications.
$ vim pv-config.yamlapiVersion: v1
kind: PersistentVolume
metadata:
name: my-volume
spec:
capacity:
storage: 3Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/app/data"$ kubectl create -f pv-config.yaml
persistentvolume/my-volume created$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
my-volume 3Gi RWO Retain Available ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ 60s$ kubectl describe pv my-volume
Labels: <none>
Annotations: <none>
Finalizers: [kubernetes.io/pv-protection]
StorageClass:
Status: Available
Claim:
Reclaim Policy: Retain
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 3Gi
Node Affinity: <none>
Message:
Source:
Type: HostPath (bare host directory volume)
Path: /app/data
HostPathType:
Events: <none>apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi$ vim pvc-config.yaml$ kubectl create -f pvc-config.yaml
persistentvolumeclaim/my-claim created$ kubectl get pvc my-claim
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
my-claim Bound my-volume 3Gi RWO 7m$ kubectl describe pvc my-claim
Name: my-claim
Namespace: default
StorageClass:
Status: Bound
Volume: my-volume
Labels: <none>
Annotations: pv.kubernetes.io/bind-completed: yes
pv.kubernetes.io/bound-by-controller: yes
Finalizers: [kubernetes.io/pvc-protection]
Capacity: 3Gi
Access Modes: RWO
VolumeMode: Filesystem
Mounted By: <none>
Events: <none>$ kubectl get pv my-volume
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM ⠀⠀⠀STORAGECLASS REASON AGE
my-volume 3Gi RWO Retain Bound default/my-claim ⠀⠀⠀ 11m$ kubectl delete pvc my-claim
persistentvolumeclaim "my-claim" deleted$ kubectl get pvc my-claim
No resources found in default namespace.$ kubectl get pv my-volume
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM ⠀⠀⠀STORAGECLASS REASON AGE
my-volume 3Gi RWO Retain Released default/my-claim ⠀⠀ 21mapiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: stclass-test
image: nginx
volumeMounts:
- mountPath: "/app/data"
name: my-volume
volumes:
- name: my-volume
persistentVolumeClaim:
claimName: my-claim $ vim pvc-pod.yaml$ kubectl create -f pvc-pod.yaml
pod/my-pod created$ kubectl get pod my-pod
NAME READY STATUS RESTARTS AGE
my-pod 1/1 Running 0 6m50s$ kubectl describe pod my-pod
Name: my-pod
Namespace: default
Priority: 0
Node: node01/172.17.0.57
Start Time: Tue, 01 Dec 2020 11:44:08 +0000
Labels: <none>
Annotations: <none>
Status: Running
IP: 10.244.1.2
IPs:
IP: 10.244.1.2
Volumes:
my-volume:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: my-claim
ReadOnly: false
default-token-nlmxj:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-nlmxj
Optional: false
QoS Class: BestEffort$ kubectl exec -it my-pod -- bin/bash
root@my-pod:/# root@my-pod:/# df -h /app/data
Filesystem Size Used Avail Use% Mountedon
/dev/mapper/host01--vg-root 191G 22G 159G 13% /app/dataroot@my-pod:/# cd /app/data
root@my-pod:/app/data# echo "I love Kubermatic" > file.txtroot@my-pod:/app/data# ls
file.txt
root@my-pod:/app/data# cat file.txt
"I love Kubermatic"
root@my-pod:/app/data# exit$ kubectl delete pod my-pod
pod "my-pod" deleted
$ kubectl get pods
No resources found in default namespace.$ kubectl create -f pvc-pod.yaml
pod/my-pod created
$ kubectl get pod my-pod
NAME READY STATUS RESTARTS AGE
my-pod 1/1 Running 0 5s$ kubectl exec -it my-pod -- bin/bash
root@my-pod:/# df -h /app/data
Filesystem Size Used Avail Use% Mountedon
/dev/mapper/host01--vg-root 191G 22G 159G 13% /app/data
root@my-pod:/# cd /app/data
root@my-pod:/app/data# ls
file.txt
root@my-pod:/app/data# cat file.txt
"I love Kubermatic"kubectl get nodes --show-labelsNAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2kubectl label nodes <your-node-name> disktype=ssdkubectl apply -f https://k8s.io/examples/pods/pod-nginx-required-affinity.yamlkubectl get pods --output=wideNAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0kubectl apply -f https://k8s.io/examples/pods/pod-nginx-preferred-affinity.yamlkubectl get pods --output=wideNAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0kind: Namespace
apiVersion: v1
metadata:
name: mynamespace
labels:
name: mynamespace
kubectl apply -f test.yamlNAME STATUS AGE
default Active 3d
kube-node-lease Active 3d
kube-public Active 3d
kube-system Active 3d
mynamespace Active 1dapiVersion: v1
kind: Pod
metadata:
name: mypod
labels:
name: mypod
spec:
containers:
—name: mypod
image: nginxkubectl apply -f pod.yaml --namespace=mynamespaceapiVersion: v1
kind: Pod
metadata:
name: mypod
namespace: mynamespace
labels:
name: mypod
...kubectl get pods --namespace=mynamespace
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "<node-ip-address>",
"labels": {
"name": "<node-logical-name>"
}
}
}kubectl taint nodes node1 key1=value1:NoSchedulekubectl taint nodes node1 key1=value1:NoSchedule-tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "example-key"
operator: "Exists"
effect: "NoSchedule"kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoScheduletolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000$ kubectl cordon node-1
node/node-1 cordoned$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node-1 Ready,SchedulingDisabled control-plane,master 26m v1.23.3$ kubectl drain node-1
node/node-1 already cordoned
evicting pod kube-system/storage-provisioner
evicting pod default/nginx-7c658794b9-zszdd
evicting pod kube-system/coredns-64897985d-dp6lx
pod/storage-provisioner evicted
pod/nginx-7c658794b9-zszdd evicted
pod/coredns-64897985d-dp6lx evicted
node/node-1 evicted$ kubectl drain node-1 --grace-period 0...contents omitted...
readinessProbe:
httpGet:
path: /health (1)
port: 8080
initialDelaySeconds: 15 (2)
timeoutSeconds: 1 (3)
...contents omitted......contents omitted...
livenessProbe:
exec:
command:(1)
- cat
- /tmp/health
initialDelaySeconds: 15
timeoutSeconds: 1
...contents omitted......contents omitted...
livenessProbe:
tcpSocket:
port: 8080 (1)
initialDelaySeconds: 15
timeoutSeconds: 1
...contents omitted...[user@host ~]$ kubectl set probe deployment myapp --readiness \
--get-url=http://:8080/healthz --period=20
[user@host ~]$ kubectl patch deployment myapp \
-p '{"spec":{"containers"[0]: {"readinessProbe": {}}}}'[user@host ~]$ kubectl set probe deployment myapp --readiness \
--get-url=http://:8080/healthz --period=20[user@host ~]$ kubectl set probe deployment myapp --liveness \
--open-tcp=3306 --period=20 \
--timeout-seconds=1[user@host ~]$ kubectl set probe deployment myapp --liveness \
--get-url=http://:8080/healthz --initial-delay-seconds=30 \
--success-threshold=1 --failure-threshold=3apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresentapiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent




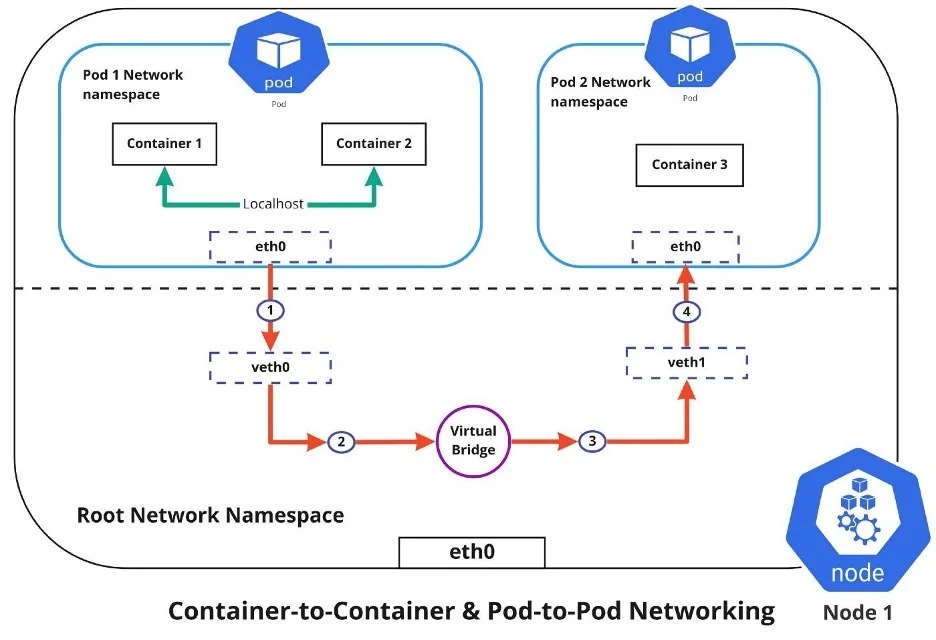
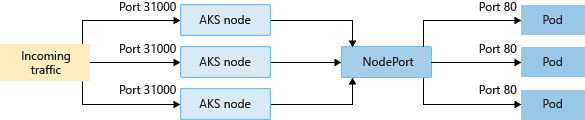
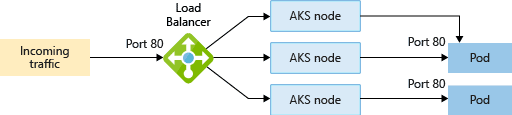
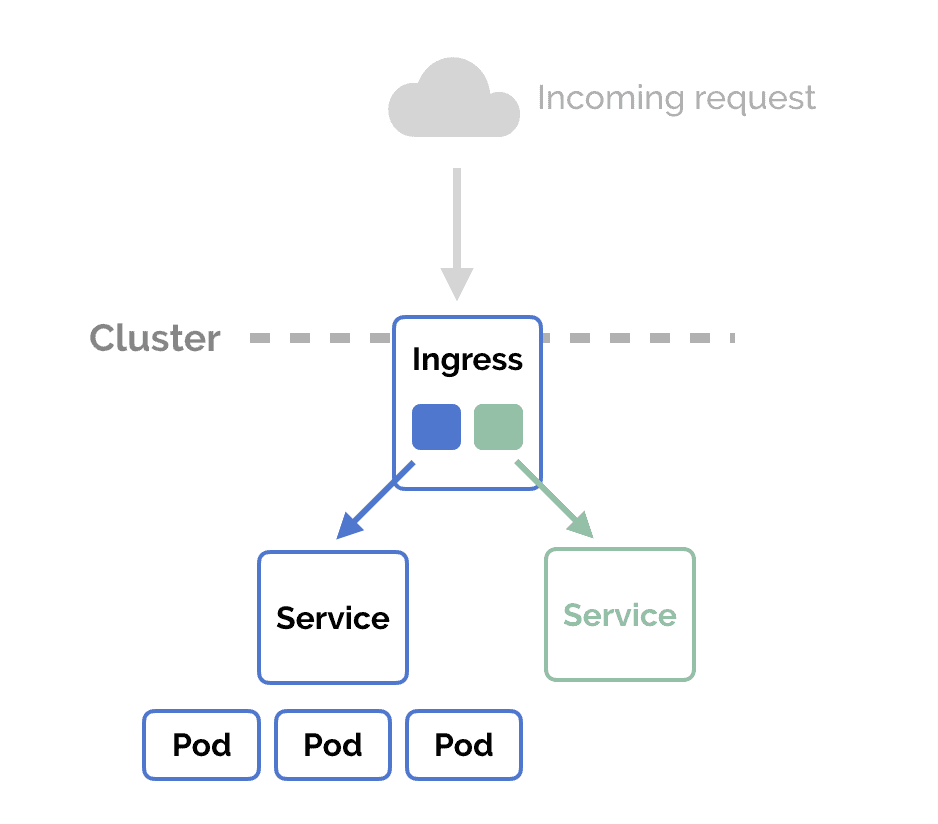
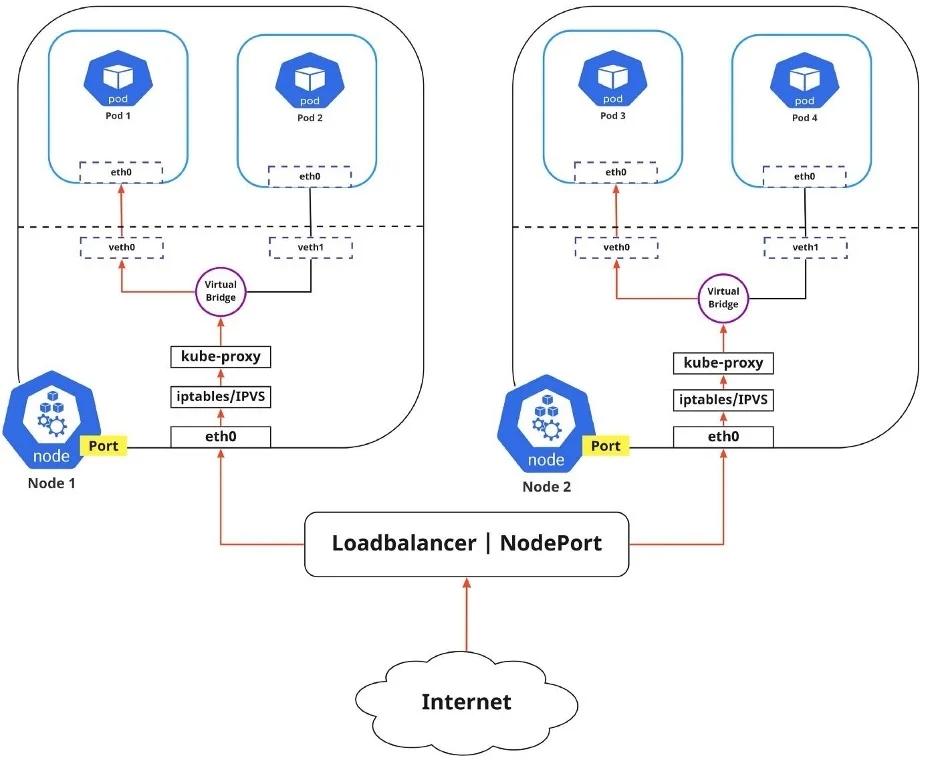
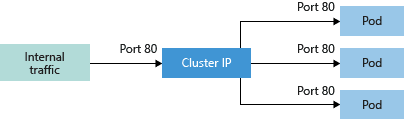
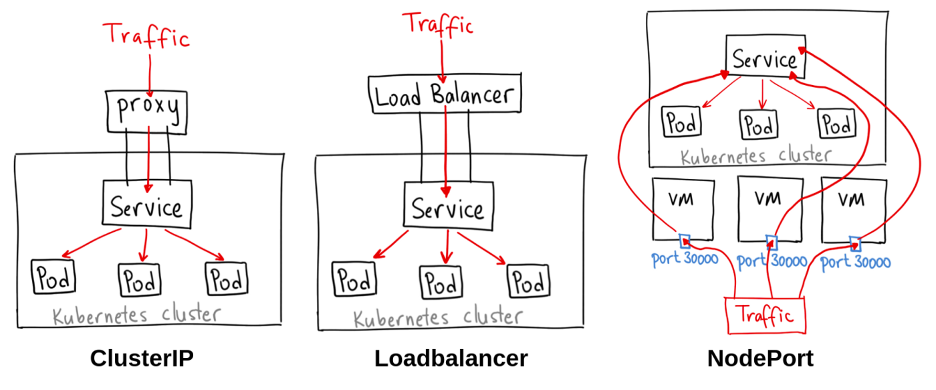
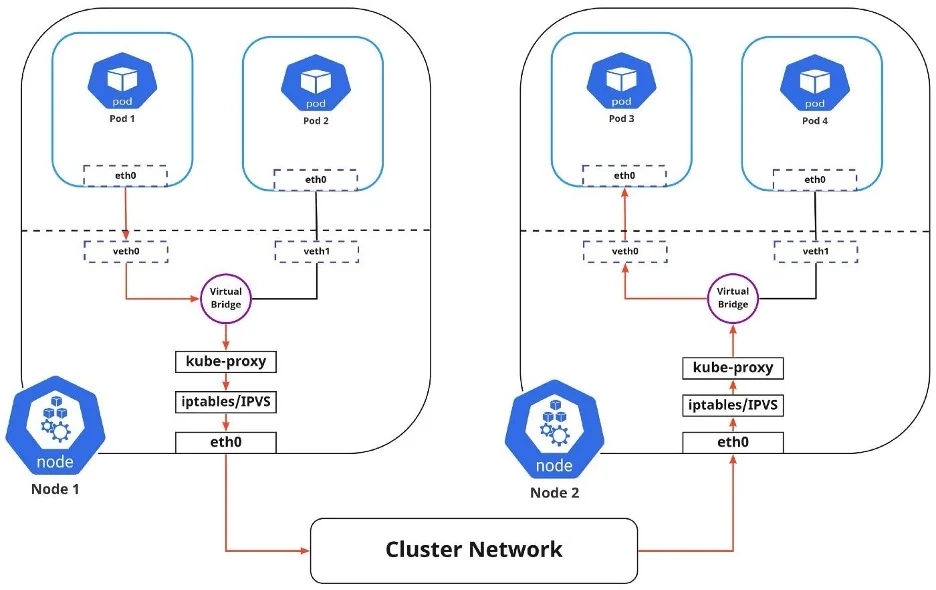









Development and Test Deployment
In Linux/Unix operating system everything is a file even directories are files, files are files, and devices like mouse, keyboard, printer, etc are also files. Here we are going to see the Directory S
Metabase is an open source business intelligence tool
Metabase.appMariaDB. One of the most popular database servers. Made by the original developers of MySQL


















Dear {last_name}, You have been invited to campaign {campaign_name}Dear john, You have been invited to campaign "First Quarter Password Awareness"apt update
apt install npm -y
npm install -g @angular/cling new my-project-nameng build --prodCopyfunction helloWorld() {
return 'Hello world!';
}Copydescribe('Hello world', () => { (1)
it('says hello', () => { (2)
expect(helloWorld()) (3)
.toEqual('Hello world!'); (4)
});
});Copyexpect(array).toContain(member);
expect(fn).toThrow(string);
expect(fn).toThrowError(string);
expect(instance).toBe(instance);
expect(mixed).toBeDefined();
expect(mixed).toBeFalsy();
expect(mixed).toBeNull();
expect(mixed).toBeTruthy();
expect(mixed).toBeUndefined();
expect(mixed).toEqual(mixed);
expect(mixed).toMatch(pattern);
expect(number).toBeCloseTo(number, decimalPlaces);
expect(number).toBeGreaterThan(number);
expect(number).toBeLessThan(number);
expect(number).toBeNaN();
expect(spy).toHaveBeenCalled();
expect(spy).toHaveBeenCalledTimes(number);
expect(spy).toHaveBeenCalledWith(...arguments);Copydescribe('Hello world', () => {
let expected = "";
beforeEach(() => {
expected = "Hello World";
});
afterEach(() => {
expected = "";
});
it('says hello', () => {
expect(helloWorld())
.toEqual(expected);
});
});Copy<link rel="stylesheet" href="jasmine.css">
<script src="jasmine.js"></script>
<script src="jasmine-html.js"></script>
<script src="boot.js"></script>Copy<link rel="stylesheet" href="jasmine.css">
<script src="jasmine.js"></script>
<script src="jasmine-html.js"></script>
<script src="boot.js"></script>
<script src="main.js"></script>Copy<link rel="stylesheet" href="jasmine.css">
<script src="jasmine.js"></script>
<script src="jasmine-html.js"></script>
<script src="boot.js"></script>
<script src="main.js"></script>
<script src="test.js"></script>$theme: (
font-main: unquote('"Segoe UI", Roboto, "Helvetica Neue", Arial, sans-serif'),
font-secondary: font-main,
font-weight-thin: 200,
font-weight-light: 300,
font-weight-normal: 400,
font-weight-bolder: 500,
font-weight-bold: 600,
font-weight-ultra-bold: 800,
base-font-size: 16px,
font-size-xlg: 1.25rem,
font-size-lg: 1.125rem,
font-size: 1rem,
font-size-sm: 0.875rem,
font-size-xs: 0.75rem,
radius: 0.375rem,
padding: 1.25rem,
margin: 1.5rem,
line-height: 1.25,
...$theme: (
font-main: unquote('"Segoe UI", Roboto, "Helvetica Neue", Arial, sans-serif'),
font-secondary: font-main, ...
header-font-family: font-secondary,
header-font-size: font-size,
header-line-height: line-height,
header-fg: color-fg-heading,
header-bg: color-bg,
header-height: 4.75rem,
header-padding: 1.25rem,
header-shadow: shadow,
...@import '../../../@theme/styles/themes';
:host {
background: nb-theme(card-bg); // and use it
}@import '../../../@theme/styles/themes';
@include nb-install-component() {
background: nb-theme(card-bg); // now, for each theme registered the corresponding value will be inserted
.container {
background: nb-theme(color-bg);
font-weight: nb-theme(font-weight-bold);
}
}{
"/api": {
"target": "http://localhost:3000",
"secure": false
}
}ng serve --proxy-config proxy.conf.jsonserver {
listen 80;
server_name website.com;
root /yourAngularAppDistPath;
index index.html index.htm;
etag on;
location / {
index index.html;
try_files $uri /index.html;
}
}server {
listen 80;
server_name website.com;
root /yourAngularAppDistPath;
index index.html index.htm;
etag on;
location / {
index index.html;
try_files $uri /index.html;
}
location /api {
proxy_pass http://localhost:3000/;
proxy_set_header Host $host;
}
}macOS: $HOME/.composer/vendor/binLinux OS: $HOME/.config/composer/vendor/bincomposer global require "laravel/installer"laravel new nirectory_namecomposer create-project laravel/laravel - prefer -distphp artisan servephp artisan key: generateAPP_ENV = local
APP_DEBUG = true
APP_KEY = base64:ZPt2wmKE/X4eEhrzJU6XX4R93rCwYG8E2f8QUA7kGK8 =
APP_URL = http://localhost
DB_CONNECTION = mysql
DB_HOST = 127.0.0.1
DB_PORT = 3306
DB_DATABASE = homestead
DB_USERNAME = homestead
DB_PASSWORD = secret
CACHE_DRIVER = file
SESSION_DRIVER = file
QUEUE_DRIVER = sync
REDIS_HOST = 127.0.0.1
REDIS_PASSWORD = null
REDIS_PORT = 6379
MAIL_DRIVER = smtp
MAIL_HOST = mailtrap.ioMAIL_PORT = 2525
MAIL_USERNAME = null
MAIL_PASSWORD = null
MAIL_ENCRYPTION = nullphp artisan downphp artisan upkubectl get nodes --show-labelsNAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,disktype=ssd,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2

































Lab1 :
- script to detect OS
- install git
- clone public project from github
- backup project dir with date
- cron job for back dir Lab2 :
- Build Docker file for Spring or Angular or laravel
- Build Docker compose for Spring or Angular or laravel Advanced Lab :
- build docker-compose project with Microservice with git submoduleNumber of portal Users [5000]
Number of concurrent users = 40 * 5000 / 100 = 2000
× Number of Woker = 2000 / 20 = 100 Woker
x Number of Workers / VM = 33
x Number of Core / VM = 16 core
x RAM cacpity estimation [ 1 core * 4 ] = 16 * 4 = 64 Gb / VM
Minimum 4 VM with 16 core / 64 Gb RAM
Recommended 5 VM x with 16 core / 64 Gb RAM
Number of Users [ 5000 ]
× Number of events per host per day [ 15 ]
× 5Kb per event
Number of Users × Number of events per host per day
× 5Kb per event
For example, an organization of 5,000 Users, with each user generating
an average of 15 events per day,
requiring a 30 day retention would require a database capacity of:
## DB stoage sizing / Month
5,000 × 15 × 5 × 30 = 11,250,000Kb, or 11Gb
## DB stoage sizing / Year
11 GB per Month x 12 = 132 Gb / Year
DB HW sizing for 5000 client connections / sec
# DB Version: 14
# OS Type: linux
# DB Type: web
# Total Memory (RAM): 96 GB
# CPUs num: 24
# Connections num: 5000
# Data Storage: san
max_connections = 5000
shared_buffers = 24GB
effective_cache_size = 72GB
maintenance_work_mem = 2GB
checkpoint_completion_target = 0.9
wal_buffers = 16MB
default_statistics_target = 100
random_page_cost = 1.1
effective_io_concurrency = 300
work_mem = 1258kB
min_wal_size = 1GB
max_wal_size = 4GB
max_worker_processes = 24
max_parallel_workers_per_gather = 4
max_parallel_workers = 24
max_parallel_maintenance_workers = 4x Number of users [ 5000 ]
× Number of survey per user per day [ 2 ]
× 25 Mb per survey attachment [ 25 mb ]
Number of Users × Number of survey per user per day
× 25 Mb per survey attachment
## File storage sizing / Month
5,000 × 2 x 25 Mb × 30 = 750 Gb
## File storage sizing / Year
750 GB per Month x 12 = 9 TB / Year
Number of portal Users [500000]
Number of concurrent users = 40 * 500000 / 100 = 200000
× Number of Woker = 200000 / 20 = 100 Woker
x Number of Workers / VM = 33
x Number of Core / VM = 16 core
x RAM cacpity estimation [ 1 core * 4 ] = 16 * 4 = 64 Gb / VM
Minimum 4 VM with 16 core / 64 Gb RAM
Recommended 5 VM x with 16 core / 64 Gb RAM
Number of Users [ 5000 ]
× Number of events per host per day [ 15 ]
× 5Kb per event
Number of Users × Number of events per host per day
× 5Kb per event
For example, an organization of 5,000 Users, with each user generating
an average of 15 events per day,
requiring a 30 day retention would require a database capacity of:
## DB stoage sizing / Month
5,000 × 15 × 5 × 30 = 11,250,000Kb, or 11Gb
## DB stoage sizing / Year
11 GB per Month x 12 = 132 Gb / Year
DB HW sizing for 5000 client connections / sec
# DB Version: 14
# OS Type: linux
# DB Type: web
# Total Memory (RAM): 96 GB
# CPUs num: 24
# Connections num: 5000
# Data Storage: san
max_connections = 5000
shared_buffers = 24GB
effective_cache_size = 72GB
maintenance_work_mem = 2GB
checkpoint_completion_target = 0.9
wal_buffers = 16MB
default_statistics_target = 100
random_page_cost = 1.1
effective_io_concurrency = 300
work_mem = 1258kB
min_wal_size = 1GB
max_wal_size = 4GB
max_worker_processes = 24
max_parallel_workers_per_gather = 4
max_parallel_workers = 24
max_parallel_maintenance_workers = 4x Number of users [ 5000 ]
× Number of survey per user per day [ 2 ]
× 25 Mb per survey attachment [ 25 mb ]
Number of Users × Number of survey per user per day
× 25 Mb per survey attachment
## File storage sizing / Month
5,000 × 2 x 25 Mb × 30 = 750 Gb
## File storage sizing / Year
750 GB per Month x 12 = 9 TB / Year
USAGE on \*.\*



./bin/build# javascript dependencies
$ yarnlein ring serveryarn build-hot$ yarn build$ yarn build-hot$ yarn build-watchyarn testlein run refresh-integration-test-db-metadata # Scan the sample dataset and re-run sync/classification/field values caching
yarn test-e2e-watch # Watches for file changes and runs the tests that have changed
yarn test-e2e-watch TestFileName # Watches the files in paths that match the given (regex) stringimport {
useSharedAdminLogin,
createTestStore,
} from "__support__/e2e";
import {
click
} from "__support__/enzyme"
import { mount } from "enzyme"
import { FETCH_DATABASES } from "metabase/redux/metadata";
import { INITIALIZE_QB } from "metabase/query_builder/actions";
import RunButton from "metabase/query_builder/components/RunButton";
describe("Query builder", () => {
beforeAll(async () => {
// Usually you want to test stuff where user is already logged in
// so it is convenient to login before any test case.
useSharedAdminLogin()
})
it("should let you run a new query", async () => {
// Create a superpowered Redux store.
// Remember `await` here!
const store = await createTestStore()
// Go to a desired path in the app. This is safest to do before mounting the app.
store.pushPath('/question')
// Get React container for the whole app and mount it using Enzyme
const app = mount(store.getAppContainer())
// Usually you want to wait until the page has completely loaded, and our way to do that is to
// wait until the completion of specified Redux actions. `waitForActions` is also useful for verifying that
// specific operations are properly executed after user interactions.
// Remember `await` here!
await store.waitForActions([FETCH_DATABASES, INITIALIZE_QB])
// You can use `enzymeWrapper.debug()` to see what is the state of DOM tree at the moment
console.log(app.debug())
// You can use `testStore.debug()` method to see which Redux actions have been dispatched so far.
// Note that as opposed to Enzyme's debugging method, you don't need to wrap the call to `console.log()`.
store.debug();
// For simulating user interactions like clicks and input events you should use methods defined
// in `enzyme.js` as they abstract away some React/Redux complexities.
click(app.find(RunButton))
// Note: In pretty rare cases where rendering the whole app is problematic or slow, you can just render a single
// React container instead with `testStore.connectContainer(container)`. In that case you are not able
// to click links that lead to other router paths.
});
})yarn test-unit # Run all tests at once
yarn test-unit-watch # Watch for file changesyarn test-karma # Run all tests once
yarn test-karma-watch # Watch for file changeslein runlein ring server# Build the 'mongo' driver
./bin/build-driver.sh mongo# Build all drivers
./bin/build-drivers.sh# Install dependencies
lein with-profiles +include-all-drivers depslein testlein test metabase.api.session-testDRIVERS=h2,postgres,mysql,mongo lein testlein eastwood && lein bikeshed && lein docstring-checker && lein check-namespace-decls && ./bin/reflection-linter(setq custom-file (concat user-emacs-directory ".custom.el")) ; tell Customize to save customizations to ~/.emacs.d/.custom.el
(ignore-errors ; load customizations from ~/.emacs.d/.custom.el
(load-file custom-file))lein instant-cheatsheetconst someString = t`Hello ${name}!`;
const someJSX = <div>{jt`Hello ${name}`}</div>;(trs "Hello {0}!" name)sudo apt-get update
sudo apt-get install mariadb-serversudo mysql_secure_installation utilitysudo ufw enable
sudo ufw allow mysqlsudo systemctl start mysqlsudo systemctl enable mysqlbind-address = 127.0.0.1 ( The default. )
bind-address = XXX.XXX.XXX.XXX ( The ip address of your Public Net interface. )
bind-address = ZZZ.ZZZ.ZZZ.ZZZ ( The ip address of your Service Net interface. )
bind-address = 0.0.0.0 ( All ip addresses. )sudo systemctl restart mysql/usr/bin/mysql -u root -pmysql>UPDATE mysql.user SET Password = PASSWORD('password') WHERE User = 'root';UPDATE mysql.user SET authentication_string = PASSWORD('password') WHERE User = 'root';SELECT User, Host, authentication_string FROM mysql.user;SELECT User, Host, authentication_string FROM mysql.user;
+------------------+-----------+-------------------------------------------+
| User | Host | authentication_string |
+------------------+-----------+-------------------------------------------+
| root | localhost | *756FEC25AC0E1823C9838EE1A9A6730A20ACDA21 |
| mysql.session | localhost | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE |
| mysql.sys | localhost | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE |
| debian-sys-maint | localhost | *27E7CA2445405AB10C656AFD0F86AF76CCC57692 |
+------------------+-----------+-------------------------------------------+CREATE DATABASE demodb;SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| demodb |
| mysql |
+--------------------+
3 rows in set (0.00 sec)INSERT INTO mysql.user (User,Host,authentication_string,ssl_cipher,x509_issuer,x509_subject)
VALUES('demouser','localhost',PASSWORD('demopassword'),'','','');FLUSH PRIVILEGES;SELECT User, Host, authentication_string FROM mysql.user;
+------------------+-----------+-------------------------------------------+
| User | Host | Password |
+------------------+-----------+-------------------------------------------+
| root | localhost | *756FEC25AC0E1823C9838EE1A9A6730A20ACDA21 |
| mysql.session | localhost | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE |
| mysql.sys | localhost | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE |
| debian-sys-maint | localhost | *27E7CA2445405AB10C656AFD0F86AF76CCC57692 |
| demouser | localhost | *0756A562377EDF6ED3AC45A00B356AAE6D3C6BB6 |
+------------------+-----------+-------------------------------------------+GRANT ALL PRIVILEGES ON demodb.* to demouser@localhost;FLUSH PRIVILEGES;SHOW GRANTS FOR 'demouser'@'localhost';
2 rows in set (0.00 sec)/etc/mysql/usr/sbin/mysqld --help --verboseDefault options are read from the following files in the given order:
/etc/my.cnf /etc/mysql/my.cnf /usr/etc/my.cnf ~/.my.cnf/etc/mysql/my.cnf/var/log/mysqllog_error = /var/log/mysql/error.log[client]
port = 3306
[mysqld]
port = 3306[mysqld]
bind-address = 127.0.0.1/var/lib/mysqlmysql -u root -p -e "FLUSH TABLES WITH READ LOCK;"mysql -u root -p -e "UNLOCK TABLES;"mysql -u root -p"password" -e "FLUSH TABLES WITH READ LOCK;"
mysql -u root -p"password" -e "UNLOCK TABLES;"mysqldump -u root -p demodb > dbbackup.sqlmysql -u root -p demodb < dbbackup.sqlsudo /etc/init.d/mysql stopsudo /etc/init.d/mysqld stopsudo mysqld_safe --skip-grant-tables &mysql -urootuse mysql;
update user set authentication_string=PASSWORD("mynewpassword") where User='root';
flush privileges;
quitsudo /etc/init.d/mysql stop
...
sudo /etc/init.d/mysql startsudo /etc/init.d/mysqld stop
...
sudo /etc/init.d/mysqld startmysql -u root -pFLUSH PRIVILEGES;+-----------------------------------------------------------------------------------------------------------------+
| Grants for demouser@localhost |
+-----------------------------------------------------------------------------------------------------------------+
| GRANT USAGE ON *.* TO 'demouser'@'localhost' IDENTIFIED BY PASSWORD '*0756A562377EDF6ED3AC45A00B356AAE6D3C6BB6' |
| GRANT ALL PRIVILEGES ON `demodb`.* TO 'demouser'@'localhost' |
+-----------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)kubectl create configmap <map-name> <data-source>apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# property-like keys; each key maps to a simple value
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# file-like keys
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=trueapiVersion: v1
kind: ConfigMap
metadata:
...
data:
...
immutable: true kubectl edit secrets mysecretkubectl create configmap language --from-literal=LANGUAGE=Spanish \
-o yaml --dry-run | kubectl replace -f -
kubectl create secret generic apikey --from-literal=API_KEY=098765 \
-o yaml --dry-run | kubectl replace -f -kubectl delete pod -l name=envtestwget https://raw.githubusercontent.com/omarabdalhamid/zisoft-scripts/master/zisoft-master.sh && sh zisoft-master.sh#!/bin/bash
################################################################################
# Script for installing ZiSoft on Ubuntu 14.04, 15.04, 16.04 and 18.04 (could be used for other version too)
# Author: OmarAbdalhamid Omar
#-------------------------------------------------------------------------------
# This script will install ZiSoft Awareness 3 on your Ubuntu 18.04 server. I
#-------------------------------------------------------------------------------
# Make a new file:
# sudo nano zisoft-install.sh
# Place this content in it and then make the file executable:
# sudo chmod +x zisoft-install.sh
# Execute the script to install zisoft:
# ./zisoft-install.sh
################################################################################
#--------------------------------------------------
# Clone ZiSoft Awareness Repo
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Clone ZiSoft branch --"
echo "\n#############################################"
sudo mkdir zisoft-test
cd zisoft-test
sudo git clone https://gitlab.com/zisoft/awareness.git
#--------------------------------------------------
# Update Server
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Download Docker Repositry --"
echo "\n#############################################"
sudo apt-get update -y
sudo apt install npm -y
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common -y
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt install gnupg2 pass -y
sudo add-apt-repository universe -y
sudo apt-get update -y
#--------------------------------------------------
# Install Docker & Docker Swarm
#--------------------------------------------------
sudo apt-get install docker-ce -y
sudo apt-get install docker-compose -y
sudo usermod -aG docker ${USER}
sudo docker login registry.gitlab.com
sudo docker swarm init
#--------------------------------------------------
# Run npm Package of ZiSoft CLI
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Download NPM Packages --"
echo "\n#############################################"
cd awareness/cli
sudo npm update
sudo npm link
cd ..
#--------------------------------------------------
# Build && Package ZiSoft Awareness Project
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Build ZiSoft APP--"
echo "\n#############################################"
sudo zisoft build --docker --sass --app --ui --composer
echo -e "\n--- Package ZiSoft APP--"
sudo zisoft package
#--------------------------------------------------
# Deploy ZiSoft Awareness Project
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Deploy ZiSoft APP--"
echo "\n#############################################"
sudo zisoft deploy --prod
sleep 3m
container_web_id="$(sudo docker ps | grep zisoft/awareness/web | awk '{print $1}')"
container_ui_id="$(sudo docker ps | grep zisoft/awareness/ui | awk '{print $1}')"
sudo docker exec -it $container_web_id bash -c 'sed -i "/zinad:lessons/a '\''campaign1'\'' => 1" app/Console/Commands/Demo.php'
sudo docker exec -it $container_web_id bash -c 'sed -i "/zinad:lessons/a '\''mode'\'' => '\''none'\''," app/Console/Commands/Demo.php'
sudo docker exec -it $container_web_id bash -c 'sed -i "/zinad:lessons/a '\''resolution'\'' => '\''720'\''," app/Console/Commands/Demo.php'
sudo docker exec -it $container_web_id bash -c 'sed -i "/zinad:lessons/a '\''version'\'' => 1," app/Console/Commands/Demo.php'
sudo docker exec -it $container_web_id bash -c "php artisan db:seed --class=init"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson browser 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson email 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson password 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson social 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson wifi 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson aml 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan db:seed --class=DropRecreateDB"
sudo docker exec -it $container_web_id bash -c "php artisan migrate"
sudo docker exec -it $container_web_id bash -c "php artisan db:seed --class=init"
sudo docker exec -it $container_web_id bash -c "php artisan zisoft:demo 100 5 30"
sudo docker restart $container_ui_id
#--------------------------------------------------
# ZiSoft Awareness Project Installed Successfully
#--------------------------------------------------
echo "\n#############################################"
echo "\n-----ZiSoft Awareness Project Installed Successfully ----"
echo "\n#############################################"wget https://raw.githubusercontent.com/omarabdalhamid/zisoft-scripts/master/zisoft-master--demo.sh && sh zisoft-master--demo.sh#!/bin/bash
################################################################################
# Script for installing ZiSoft on Ubuntu 14.04, 15.04, 16.04 and 18.04 (could be used for other version too)
# Author: OmarAbdalhamid Omar
#-------------------------------------------------------------------------------
# This script will install ZiSoft Awareness 3 on your Ubuntu 18.04 server. I
#-------------------------------------------------------------------------------
# Make a new file:
# sudo nano zisoft-install.sh
# Place this content in it and then make the file executable:
# sudo chmod +x zisoft-install.sh
# Execute the script to install zisoft:
# ./zisoft-install.sh
################################################################################
#--------------------------------------------------
# Clone ZiSoft Awareness Repo
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Clone ZiSoft branch --"
echo "\n#############################################"
sudo mkdir zisoft-test
cd zisoft-test
sudo git clone https://gitlab.com/zisoft/awareness.git
#--------------------------------------------------
# Update Server
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Download Docker Repositry --"
echo "\n#############################################"
sudo apt-get update -y
sudo apt install npm -y
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common -y
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt install gnupg2 pass -y
sudo add-apt-repository universe -y
sudo apt-get update -y
#--------------------------------------------------
# Install Docker & Docker Swarm
#--------------------------------------------------
sudo apt-get install docker-ce -y
sudo apt-get install docker-compose -y
sudo usermod -aG docker ${USER}
sudo docker login registry.gitlab.com
sudo docker swarm init
#--------------------------------------------------
# Run npm Package of ZiSoft CLI
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Download NPM Packages --"
echo "\n#############################################"
cd awareness/cli
sudo npm update
sudo npm link
cd ..
#--------------------------------------------------
# Build && Package ZiSoft Awareness Project
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Build ZiSoft APP--"
echo "\n#############################################"
sudo zisoft build --docker --sass --app --ui --composer
echo -e "\n--- Package ZiSoft APP--"
sudo zisoft package
#--------------------------------------------------
# Deploy ZiSoft Awareness Project
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Deploy ZiSoft APP--"
echo "\n#############################################"
sudo zisoft deploy --prod
sleep 3m
container_web_id="$(sudo docker ps | grep zisoft/awareness/web | awk '{print $1}')"
container_ui_id="$(sudo docker ps | grep zisoft/awareness/ui | awk '{print $1}')"
sudo docker exec -it $container_web_id bash -c 'sed -i "/zinad:lessons/a '\''campaign1'\'' => 1" app/Console/Commands/Demo.php'
sudo docker exec -it $container_web_id bash -c 'sed -i "/zinad:lessons/a '\''mode'\'' => '\''none'\''," app/Console/Commands/Demo.php'
sudo docker exec -it $container_web_id bash -c 'sed -i "/zinad:lessons/a '\''resolution'\'' => '\''720'\''," app/Console/Commands/Demo.php'
sudo docker exec -it $container_web_id bash -c 'sed -i "/zinad:lessons/a '\''version'\'' => 1," app/Console/Commands/Demo.php'
sudo docker exec -it $container_web_id bash -c "php artisan db:seed --class=init"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson browser 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson email 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson password 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson social 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson wifi 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson aml 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lessons 720 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan db:seed --class=DropRecreateDB"
sudo docker exec -it $container_web_id bash -c "php artisan migrate"
sudo docker exec -it $container_web_id bash -c "php artisan db:seed --class=init"
sudo docker exec -it $container_web_id bash -c "php artisan zisoft:demo 100 5 30"
sudo docker restart $container_ui_id
curl -L https://downloads.portainer.io/portainer-agent-stack.yml -o portainer-agent-stack.yml
sudo docker stack deploy --compose-file=portainer-agent-stack.yml portainer
#--------------------------------------------------
# ZiSoft Awareness Project Installed Successfully
#--------------------------------------------------
echo "\n#############################################"
echo "\n-----ZiSoft Awareness Project Installed Successfully ----"
echo "\n#############################################"
wget https://raw.githubusercontent.com/omarabdalhamid/zisoft-scripts/master/zisoft-branch.sh && sh zisoft-branch.sh#!/bin/bash
################################################################################
# Script for installing ZiSoft on Ubuntu 14.04, 15.04, 16.04 and 18.04 (could be used for other version too)
# Author: OmarAbdalhamid Omar
#-------------------------------------------------------------------------------
# This script will install ZiSoft Awareness 3 on your Ubuntu 18.04 server. I
#-------------------------------------------------------------------------------
# Make a new file:
# sudo nano zisoft-branch.sh
# Place this content in it and then make the file executable:
# sudo chmod +x zisoft-install.sh
# Execute the script to install zisoft:
# ./zisoft-branch.sh
################################################################################
echo "\n#############################################"
echo "\n--- Installing ZiSoft From Branch --"
echo "\n#############################################"
read -p "Enter ZiSoft Awareness Branch Name : " release_date
#--------------------------------------------------
# Clone ZiSoft Awareness Repo
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Clone ZiSoft branch --"
echo "\n#############################################"
sudo mkdir zisoft-test
cd zisoft-test
sudo git clone https://gitlab.com/zisoft/awareness.git --branch $release_date
#--------------------------------------------------
# Update Server
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Download Docker Repositry --"
echo "\n#############################################"
sudo apt-get update -y
sudo apt install npm -y
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common -y
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt install gnupg2 pass -y
sudo add-apt-repository universe -y
sudo apt-get update -y
#--------------------------------------------------
# Install Docker & Docker Swarm
#--------------------------------------------------
sudo apt-get install docker-ce -y
sudo apt-get install docker-compose -y
sudo usermod -aG docker ${USER}
sudo docker login registry.gitlab.com
sudo docker swarm init
#--------------------------------------------------
# Run npm Package of ZiSoft CLI
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Download NPM Packages --"
echo "\n#############################################"
cd awareness/cli
sudo npm update
sudo npm link
cd ..
#--------------------------------------------------
# Build && Package ZiSoft Awareness Project
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Build ZiSoft APP--"
echo "\n#############################################"
sudo zisoft build --docker --sass --app --ui --composer
echo -e "\n--- Package ZiSoft APP--"
sudo zisoft package
#--------------------------------------------------
# Deploy ZiSoft Awareness Project
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Deploy ZiSoft APP--"
echo "\n#############################################"
sudo zisoft deploy --prod
sleep 3m
container_web_id="$(sudo docker ps | grep zisoft/awareness/web | awk '{print $1}')"
container_ui_id="$(sudo docker ps | grep zisoft/awareness/ui | awk '{print $1}')"
sudo docker exec -it $container_web_id bash -c "php artisan db:seed --class=init"
sudo docker restart $container_ui_id
#--------------------------------------------------
# ZiSoft Awareness Project Installed Successfully
#--------------------------------------------------
echo "\n#############################################"
echo "\n-----ZiSoft Awareness Project Installed Successfully ----"
echo "\n#############################################"wget https://raw.githubusercontent.com/omarabdalhamid/zisoft-scripts/master/zisoft-branch-demo.sh && sh zisoft-branch-demo.sh #!/bin/bash
################################################################################
# Script for installing ZiSoft on Ubuntu 14.04, 15.04, 16.04 and 18.04 (could be used for other version too)
# Author: OmarAbdalhamid Omar
#-------------------------------------------------------------------------------
# This script will install ZiSoft Awareness 3 on your Ubuntu 18.04 server. I
#-------------------------------------------------------------------------------
# Make a new file:
# sudo nano zisoft-install.sh
# Place this content in it and then make the file executable:
# sudo chmod +x zisoft-install.sh
# Execute the script to install zisoft:
# ./zisoft-install.sh
################################################################################
echo "\n#############################################"
echo "\n--- Installing ZiSoft From Branch --"
echo "\n#############################################"
read -p "Enter ZiSoft Awareness Branch Name : " release_date
#--------------------------------------------------
# Clone ZiSoft Awareness Repo
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Clone ZiSoft branch --"
echo "\n#############################################"
sudo mkdir zisoft-test
cd zisoft-test
sudo git clone https://gitlab.com/zisoft/awareness.git --branch $release_date
#--------------------------------------------------
# Update Server
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Download Docker Repositry --"
echo "\n#############################################"
sudo apt-get update -y
sudo apt install npm -y
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common -y
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt install gnupg2 pass -y
sudo add-apt-repository universe -y
sudo apt-get update -y
#--------------------------------------------------
# Install Docker & Docker Swarm
#--------------------------------------------------
sudo apt-get install docker-ce -y
sudo apt-get install docker-compose -y
sudo usermod -aG docker ${USER}
sudo docker login registry.gitlab.com
sudo docker swarm init
#--------------------------------------------------
# Run npm Package of ZiSoft CLI
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Download NPM Packages --"
echo "\n#############################################"
cd awareness/cli
sudo npm update
sudo npm link
cd ..
#--------------------------------------------------
# Build && Package ZiSoft Awareness Project
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Build ZiSoft APP--"
echo "\n#############################################"
sudo zisoft build --docker --sass --app --ui --composer
echo -e "\n--- Package ZiSoft APP--"
sudo zisoft package
#--------------------------------------------------
# Deploy ZiSoft Awareness Project
#--------------------------------------------------
echo "\n#############################################"
echo "\n--- Deploy ZiSoft APP--"
echo "\n#############################################"
sudo zisoft deploy --prod
sleep 3m
container_web_id="$(sudo docker ps | grep zisoft/awareness/web | awk '{print $1}')"
container_ui_id="$(sudo docker ps | grep zisoft/awareness/ui | awk '{print $1}')"
sudo docker exec -it $container_web_id bash -c 'sed -i "/zinad:lessons/a '\''campaign1'\'' => 1" app/Console/Commands/Demo.php'
sudo docker exec -it $container_web_id bash -c 'sed -i "/zinad:lessons/a '\''mode'\'' => '\''none'\''," app/Console/Commands/Demo.php'
sudo docker exec -it $container_web_id bash -c 'sed -i "/zinad:lessons/a '\''resolution'\'' => '\''720'\''," app/Console/Commands/Demo.php'
sudo docker exec -it $container_web_id bash -c 'sed -i "/zinad:lessons/a '\''version'\'' => 1," app/Console/Commands/Demo.php'
sudo docker exec -it $container_web_id bash -c "php artisan db:seed --class=init"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson browser 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson email 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson password 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson social 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson wifi 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lesson aml 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan zinad:lessons 720 1 720 prod"
sudo docker exec -it $container_web_id bash -c "php artisan db:seed --class=DropRecreateDB"
sudo docker exec -it $container_web_id bash -c "php artisan migrate"
sudo docker exec -it $container_web_id bash -c "php artisan db:seed --class=init"
sudo docker exec -it $container_web_id bash -c "php artisan zisoft:demo 100 5 30"
sudo docker restart $container_ui_id
curl -L https://downloads.portainer.io/portainer-agent-stack.yml -o portainer-agent-stack.yml
sudo docker stack deploy --compose-file=portainer-agent-stack.yml portainer
#--------------------------------------------------
# ZiSoft Awareness Project Installed Successfully
#--------------------------------------------------
echo "\n#############################################"
echo "\n-----ZiSoft Awareness Project Installed Successfully ----"
echo "\n#############################################"wget https://raw.githubusercontent.com/omarabdalhamid/Kubernetes-install/master/kmaster.sh && sh kmaster.sh#!/bin/bash
apt-get update -y
apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common -y
apt install ntp -y
apt install libltdl7 -y
service ntp start
systemctl enable ntp
#curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add - \
# && sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable" \
# && sudo apt-get update \
# && sudo apt-get install docker-ce=18.03.1~ce-0~ubuntu -yq
sudo wget https://download.docker.com/linux/ubuntu/dists/bionic/pool/stable/amd64/docker-ce-cli_18.09.0~3-0~ubuntu-bionic_amd64.deb
sudo dpkg -i docker-ce-cli_18.09.0~3-0~ubuntu-bionic_amd64.deb
sudo add-apt-repository universe -y
apt-get install docker-compose -y
curl -L https://github.com/docker/machine/releases/download/v0.13.0/docker-machine-`uname -s`-`uname -m` >/tmp/docker-machine && \
chmod +x /tmp/docker-machine && \
sudo cp /tmp/docker-machine /usr/local/bin/docker-machine
service docker start
systemctl enable docker
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
mkdir -p /etc/systemd/system/docker.service.d
# Restart docker.
systemctl daemon-reload
systemctl restart docker
apt-get update && apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt-get update
apt-get install -y kubelet kubeadm kubectl
apt-mark hold kubelet kubeadm kubectl
kubeadm init --token=102952.1a7dd4cc8d1f4cc5 --kubernetes-version $(kubeadm version -o short)
sudo cp /etc/kubernetes/admin.conf $HOME/
sudo chown $(id -u):$(id -g) $HOME/admin.conf
export KUBECONFIG=$HOME/admin.conf
kubectl taint nodes --all node-role.kubernetes.io/master-wget https://raw.githubusercontent.com/omarabdalhamid/Kubernetes-install/master/knode2.sh && sh knode2.sh #!/bin/bash
apt-get update -y
apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common -y
apt install ntp -y
service ntp start
systemctl enable ntp
# Install Docker CE
## Set up the repository:
### Install packages to allow apt to use a repository over HTTPS
### Add Docker’s official GPG key
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add -
### Add Docker apt repository.
add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
## Install Docker CE.
apt-get update && apt-get install docker-ce=18.06.2~ce~3-0~ubuntu
# Setup daemon.
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
mkdir -p /etc/systemd/system/docker.service.d
# Restart docker.
systemctl daemon-reload
systemctl restart docker
sudo add-apt-repository universe -y
apt-get install docker-compose -y
curl -L https://github.com/docker/machine/releases/download/v0.13.0/docker-machine-`uname -s`-`uname -m` >/tmp/docker-machine && \
chmod +x /tmp/docker-machine && \
sudo cp /tmp/docker-machine /usr/local/bin/docker-machine
service docker start
systemctl enable docker
apt-get update && apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt-get update
apt-get install -y kubelet kubeadm kubectl
apt-mark hold kubelet kubeadm kubectl
wget https://raw.githubusercontent.com/omarabdalhamid/Kubernetes-install/master/kube-network.yaml && kubectl apply -f kube-network.yaml apiVersion: v1
kind: List
items:
- apiVersion: v1
kind: ServiceAccount
metadata:
name: weave-net
labels:
name: weave-net
namespace: kube-system
- apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: weave-net
labels:
name: weave-net
rules:
- apiGroups:
- ''
resources:
- pods
- namespaces
- nodes
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- networkpolicies
verbs:
- get
- list
- watch
- apiGroups:
- 'networking.k8s.io'
resources:
- networkpolicies
verbs:
- get
- list
- watch
- apiGroups:
- ''
resources:
- nodes/status
verbs:
- patch
- update
- apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: weave-net
labels:
name: weave-net
roleRef:
kind: ClusterRole
name: weave-net
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: weave-net
namespace: kube-system
- apiVersion: rbac.authorization.k8s.io/v1beta1
kind: Role
metadata:
name: weave-net
namespace: kube-system
labels:
name: weave-net
rules:
- apiGroups:
- ''
resources:
- configmaps
resourceNames:
- weave-net
verbs:
- get
- update
- apiGroups:
- ''
resources:
- configmaps
verbs:
- create
- apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: weave-net
namespace: kube-system
labels:
name: weave-net
roleRef:
kind: Role
name: weave-net
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: weave-net
namespace: kube-system
- apiVersion: apps/v1
kind: DaemonSet
metadata:
name: weave-net
labels:
name: weave-net
namespace: kube-system
spec:
# Wait 5 seconds to let pod connect before rolling next pod
minReadySeconds: 5
selector:
matchLabels:
name: weave-net
template:
metadata:
labels:
name: weave-net
spec:
containers:
- name: weave
command:
- /home/weave/launch.sh
env:
- name: HOSTNAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
image: 'weaveworks/weave-kube:2.5.1'
imagePullPolicy: IfNotPresent
readinessProbe:
httpGet:
host: 127.0.0.1
path: /status
port: 6784
resources:
requests:
cpu: 10m
securityContext:
privileged: true
volumeMounts:
- name: weavedb
mountPath: /weavedb
- name: cni-bin
mountPath: /host/opt
- name: cni-bin2
mountPath: /host/home
- name: cni-conf
mountPath: /host/etc
- name: dbus
mountPath: /host/var/lib/dbus
- name: lib-modules
mountPath: /lib/modules
- name: xtables-lock
mountPath: /run/xtables.lock
readOnly: false
- name: weave-npc
env:
- name: HOSTNAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
image: 'weaveworks/weave-npc:2.5.1'
imagePullPolicy: IfNotPresent
#npc-args
resources:
requests:
cpu: 10m
securityContext:
privileged: true
volumeMounts:
- name: xtables-lock
mountPath: /run/xtables.lock
readOnly: false
hostNetwork: true
hostPID: true
restartPolicy: Always
securityContext:
seLinuxOptions: {}
serviceAccountName: weave-net
tolerations:
- effect: NoSchedule
operator: Exists
volumes:
- name: weavedb
hostPath:
path: /var/lib/weave
- name: cni-bin
hostPath:
path: /opt
- name: cni-bin2
hostPath:
path: /home
- name: cni-conf
hostPath:
path: /etc
- name: dbus
hostPath:
path: /var/lib/dbus
- name: lib-modules
hostPath:
path: /lib/modules
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate
updateStrategy:
type: RollingUpdatekubectl cluster-info kubectl get node -o wide kubectl get pods -n kube-system -o wide git clone https://github.com/rook/rook.git
cd rook/cluster/examples/kubernetes/ceph/
kubectl create -f operator.yaml
kubectl create -f cluster.yaml
kubectl -n rook-ceph-system get pod
kubectl apply -f toolbox.yaml kubectl exec -n rook-ceph rook-ceph-tools-856c5bc6b4-7bvf4 ceph status wget https://raw.githubusercontent.com/omarabdalhamid/Kubernetes-install/master/dashboard.yaml && kubectl apply -f dashboard.yaml # Copyright 2017 The Kubernetes Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
apiVersion: v1
kind: Namespace
metadata:
name: kubernetes-dashboard
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: LoadBalancer
ports:
- port: 443
targetPort: 8443
nodePort: 31000
selector:
k8s-app: kubernetes-dashboard
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-certs
namespace: kubernetes-dashboard
type: Opaque
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-csrf
namespace: kubernetes-dashboard
type: Opaque
data:
csrf: ""
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-key-holder
namespace: kubernetes-dashboard
type: Opaque
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-settings
namespace: kubernetes-dashboard
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
rules:
# Allow Dashboard to get, update and delete Dashboard exclusive secrets.
- apiGroups: [""]
resources: ["secrets"]
resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs", "kubernetes-dashboard-csrf"]
verbs: ["get", "update", "delete"]
# Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map.
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["kubernetes-dashboard-settings"]
verbs: ["get", "update"]
# Allow Dashboard to get metrics.
- apiGroups: [""]
resources: ["services"]
resourceNames: ["heapster", "dashboard-metrics-scraper"]
verbs: ["proxy"]
- apiGroups: [""]
resources: ["services/proxy"]
resourceNames: ["heapster", "http:heapster:", "https:heapster:", "dashboard-metrics-scraper", "http:dashboard-metrics-scraper"]
verbs: ["get"]
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
rules:
# Allow Metrics Scraper to get metrics from the Metrics server
- apiGroups: ["metrics.k8s.io"]
resources: ["pods", "nodes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kubernetes-dashboard
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kubernetes-dashboard
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kubernetes-dashboard
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
spec:
containers:
- name: kubernetes-dashboard
image: kubernetesui/dashboard:v2.0.0-beta5
imagePullPolicy: Always
ports:
- containerPort: 8443
protocol: TCP
args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
# Uncomment the following line to manually specify Kubernetes API server Host
# If not specified, Dashboard will attempt to auto discover the API server and connect
# to it. Uncomment only if the default does not work.
# - --apiserver-host=http://my-address:port
volumeMounts:
- name: kubernetes-dashboard-certs
mountPath: /certs
# Create on-disk volume to store exec logs
- mountPath: /tmp
name: tmp-volume
livenessProbe:
httpGet:
scheme: HTTPS
path: /
port: 8443
initialDelaySeconds: 30
timeoutSeconds: 30
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 1001
runAsGroup: 2001
volumes:
- name: kubernetes-dashboard-certs
secret:
secretName: kubernetes-dashboard-certs
- name: tmp-volume
emptyDir: {}
serviceAccountName: kubernetes-dashboard
nodeSelector:
"beta.kubernetes.io/os": linux
# Comment the following tolerations if Dashboard must not be deployed on master
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: dashboard-metrics-scraper
name: dashboard-metrics-scraper
namespace: kubernetes-dashboard
spec:
type: LoadBalancer
ports:
- port: 8000
targetPort: 8000
nodePort: 31001
selector:
k8s-app: dashboard-metrics-scraper
---
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: dashboard-metrics-scraper
name: dashboard-metrics-scraper
namespace: kubernetes-dashboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: dashboard-metrics-scraper
template:
metadata:
labels:
k8s-app: dashboard-metrics-scraper
annotations:
seccomp.security.alpha.kubernetes.io/pod: 'runtime/default'
spec:
containers:
- name: dashboard-metrics-scraper
image: kubernetesui/metrics-scraper:v1.0.1
ports:
- containerPort: 8000
protocol: TCP
livenessProbe:
httpGet:
scheme: HTTP
path: /
port: 8000
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- mountPath: /tmp
name: tmp-volume
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 1001
runAsGroup: 2001
serviceAccountName: kubernetes-dashboard
nodeSelector:
"beta.kubernetes.io/os": linux
# Comment the following tolerations if Dashboard must not be deployed on master
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
volumes:
- name: tmp-volume
emptyDir: {}kubectl describe secret admin-user -n kube-system wget https://raw.githubusercontent.com/omarabdalhamid/zisoft-scripts/master/zisoft-licenses-date.sh && sh zisoft-licenses-date.sh#!/bin/bash
################################################################################
# Script for installing ZiSoft on Ubuntu 14.04, 15.04, 16.04 and 18.04 (could be used for other version too)
# Author: OmarAbdalhamid Omar
#-------------------------------------------------------------------------------
# This script will install ZiSoft Awareness 3 on your Ubuntu 18.04 server. I
#-------------------------------------------------------------------------------
# Make a new file:
# sudo nano zisoft-install.sh
# Place this content in it and then make the file executable:
# sudo chmod +x zisoft-licenses.sh
# Execute the script to install zisoft:
# ./zisoft-licenses.sh
################################################################################
echo "\n#############################################"
echo "\n--- Generate ZiSoft Licenses --"
echo "\n#############################################"
read -p "\nEnter ZiSoft Awareness Client Name : " client_name
read -p "\nEnter Number of Users : " client_users
read -p "\nEnter Number of Phishing_Users : " phishing_users
read -p "\nEnter End date (YYYY-MM-DD) : " $end_date
read -p "\nEnter Phishing End date (YYYY-MM-DD) : " $phishing_date
container_web_id="$(sudo docker ps | grep zisoft/awareness/web | awk '{print $1}')"
sudo docker exec -it $container_web_id bash -c "php artisan zisoft:license_create $client_name $end_date $client_users $phishing_date $phishing_users"
echo "\n#############################################"
echo "\n--- ZiSoft Licenses Created Successfully --"
echo "\n#############################################"
echo "\n Licenses Import instructions"
echo "\n 1 - Copy Licenses Activation Key"
echo "\n 2 - Login with an admin account"
echo "\n 3 - Go to Administrator -> Settings -> Licenses"
echo "\n 4 - Click + Import License"
echo '\n 5 - paste the activation key which looks like {"users": X, "client": XXXX, "date": XXXX}XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
echo "\n 6 - Click Save"